python爬虫数据解析xpath运用
发布时间:2025-02-17 20:55
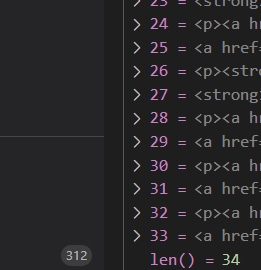
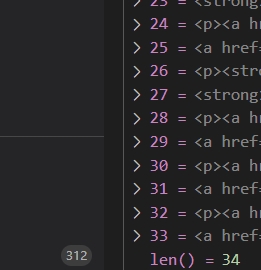
只获取内容中第一层的元素节点使用 > *
bson091723 = BeautifulSoup(
res091723.content.decode(
res090949.apparent_encoding.lower(),
"ignore",
),
"lxml",
)
bson091723.select('div[class="content"] > *')使用>*只会获取标签为 <div class="content"></div>中第一层的元素,但如果第一层中包含下层元素,也会附带获取,但是如果你不写 > 号,只写了 *号,则列表中会把所有的元素都列出来,这样就没有了层次了。你可以试一下 带有大于号和不带大于号的区别。可能我的表达不太清楚。